7. ML Strategy(1)
为什么是ML策略?(Why ML Strategy?)
如何更快速高效地优化你的机器学习系统.

正交化(Orthogonalization)
清楚要调整什么来达到某个效果, 这个步骤称之为正交化.
Orthogonalization or orthogonality is a system design property that assures that modifying an instruction or a component of an algorithm will not create or propagate side effects to other components of the system. It becomes easier to verify the algorithms independently from one another, it reduces testing and development time.
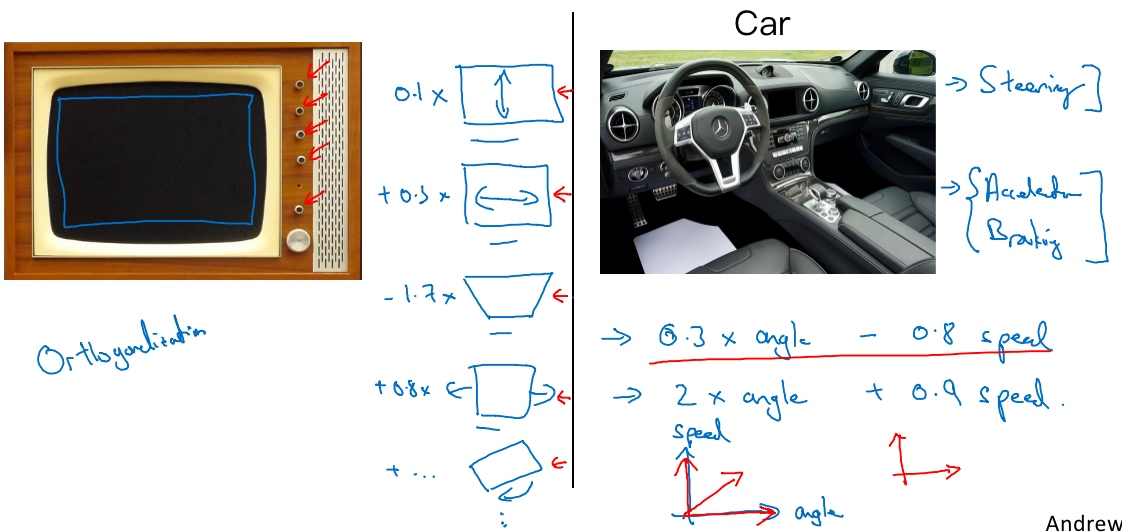
辆车有三个主要控制, 方向盘,油门和刹车. 若有一个旋钮的是0.3*angle - 0.8*speed, 它可以同时控制速度和方向, 但这却很难调整到你希望得到的角度和速度; 这样比单独分开控制转向角度和速度要难得多.
所以正交化的概念是指,你可以想出一个维度,这个维度你想做的是控制转向角,还有另一个维度来控制你的速度,那么你就需要一个旋钮尽量只控制转向角,另一个旋钮,在这个开车的例子里其实是油门和刹车控制了你的速度。但如果你有一个控制旋钮将两者混在一起,比如说这样一个控制装置同时影响你的转向角和速度,同时改变了两个性质,那么就很难令你的车子以想要的速度和角度前进。然而正交化之后,正交意味着互成90度。设计出正交化的控制装置,最理想的情况是和你实际想控制的性质一致,这样你调整参数时就容易得多。可以单独调整转向角,还有你的油门和刹车,令车子以你想要的方式运动。
When a supervised learning system is design, these are the 4 assumptions that needs to be true and orthogonal.

- Fit training set well in cost function
- If it doesn’t fit well, the use of a bigger neural network or switching to a better optimization algorithm might help.
- Fit development set well on cost function
- If it doesn’t fit well, regularization or using bigger training set might help.
- Fit test set well on cost function
- If it doesn’t fit well, then use of a bigger development set might help
- Performs well in real world
- If it doesn’t perform well, the development test set is not set correctly or the cost function is not evaluating the right thing.
单一数字评估指标(Single number evaluation metric)
通过单实数评估指标来评判模型的好坏.
To choose a classifier, a well-defined development set and an evaluation metric speed up the iteration process. Example : Cat vs Non-cat
y = 1, cat image detected
Col: Actual class y
Row: Prediction y`
| 1 | 0 | |
|---|---|---|
| 1 | True positive | False positive |
| 0 | False negative | True negative |
Precision
- Of all the images we predicted y=1, what fraction of it have cats?
- 查准率的定义是在你的分类器标记为猫的例子中,有多少真的是猫
$$Precision(\%) = \frac{𝑇𝑟𝑢𝑒\; 𝑝𝑜𝑠𝑖𝑡𝑖𝑣𝑒}{𝑁𝑢𝑚𝑏𝑒𝑟\; 𝑜𝑓\; 𝑝𝑟𝑒𝑑𝑖𝑐𝑡𝑒𝑑\; 𝑝𝑜𝑠𝑖𝑡𝑖𝑣𝑒} * 100 = \frac{𝑇𝑟𝑢𝑒\; 𝑝𝑜𝑠𝑖𝑡𝑖𝑣𝑒}{(𝑇𝑟𝑢𝑒\; 𝑝𝑜𝑠𝑖𝑡𝑖𝑣𝑒+𝐹𝑎𝑙𝑠𝑒\; 𝑝𝑜𝑠𝑖𝑡𝑖𝑣𝑒)}*100$$
Recall
- Of all the images that actually have cats, what fraction of it did we correctly identifying have cats?
- 查全率就是,对于所有真猫的图片,你的分类器正确识别出了多少百分比
$$Recall(\%) = \frac{𝑇𝑟𝑢𝑒\; 𝑝𝑜𝑠𝑖𝑡𝑖𝑣𝑒}{𝑁𝑢𝑚𝑏𝑒𝑟\; 𝑜𝑓\; 𝑝𝑟𝑒𝑑𝑖𝑐𝑡𝑒𝑑\; actually\; 𝑝𝑜𝑠𝑖𝑡𝑖𝑣𝑒} * 100 = \frac{𝑇𝑟𝑢𝑒\; 𝑝𝑜𝑠𝑖𝑡𝑖𝑣𝑒}{(𝑇𝑟𝑢𝑒\; 𝑝𝑜𝑠𝑖𝑡𝑖𝑣𝑒+True\; negative)}*100$$
Let’s compare 2 classifiers A and B used to evaluate if there are cat images:
| Classifier | Precision (p) | Recall ® |
|---|---|---|
| A | 95% | 98% |
| B | 90% | 85% |
In this case the evaluation metrics are precision and recall.
For classifier A, there is a 95% chance that there is a cat in the image and a 90% chance that it has correctly detected a cat. Whereas for classifier B there is a 98% chance that there is a cat in the image and a 85% chance that it has correctly detected a cat.
The problem with using precision/recall as the evaluation metric is that you are not sure which one is better since in this case, both of them have a good precision et recall(查准率和查全率之间往往需要折衷,两个指标都要顾及到). F1-score, a harmonic mean(调和平均数), combine both precision and recall(可以认为这是查准率P和查全率R的平均值).
$$F1-Score= \frac{2}{\frac{1}{p}-\frac{1}{r}}$$
| Classifier | Precision (p) | Recall ® | F1-Score |
|---|---|---|---|
| A | 95% | 98% | 92.4% |
| B | 90% | 85% | 91.0% |
Classifier A is a better choice. F1-Score is not the only evaluation metric that can be use, the average, for example, could also be an indicator of which classifier to use.
Another example:
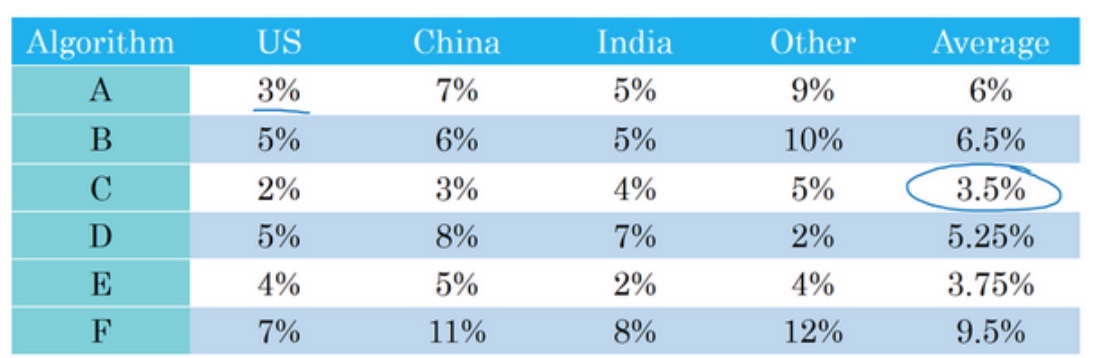
假设平均表现是一个合理的单实数评估指标,通过计算平均值,你就可以快速判断.
满足和优化指标(Satisficing and optimizing metrics)
There are different metrics to evaluate the performance of a classifier, they are called evaluation matrices(评估指标). They can be categorized as satisficing and optimizing matrices. It is important to note that these evaluation matrices must be evaluated on a training set, a development set or on the test set.
Example: Cat VS Non-Cat
| Classifier | Accuracy | Running Time |
|---|---|---|
| A | 90% | 80ms |
| B | 92% | 95ms |
| C | 95% | 1500ms |
In this case, accuracy and running time are the evaluation matrices(将准确度和运行时间组合成一个整体评估指标). Accuracy is the optimizing metric, because you want the classifier to correctly detect a cat image as accurately as possible(最大限度提高准确度). The running time which is set to be under 100 ms in this example, is the satisficing metric which mean that the metric has to meet expectation set(满足运行时间要求).
在这种情况下分类器B最好,因为在所有的运行时间都小于100毫秒的分类器中,它的准确度最好
The general rule is:

如果要考虑N个指标,有时候选择其中一个指标做为优化指标是合理的. 所以想尽量优化那个指标,然后剩下N-1个指标都是满足指标,意味着只要它们达到一定阈值, 不在乎它超过那个门槛之后的表现,但它们必须达到这个门槛.

训练/开发/测试集划分(Train/dev/test distributions)
Setting up the training, development and test sets have a huge impact on productivity. It is important to choose the development and test sets from the same distribution and it must be taken randomly from all the data.
Setting up the dev set, as well as the evaluation metric, is really defining what target you want to aim at.
Guideline
Choose a development set and test set(come from the same distribution) to reflect data you expect to get in the future and consider important to do well.
开发集和测试集的大小(Size of dev and test sets)
Old way of splitting data
We had smaller data set therefore we had to use a greater percentage of data to develop and test ideas and models.
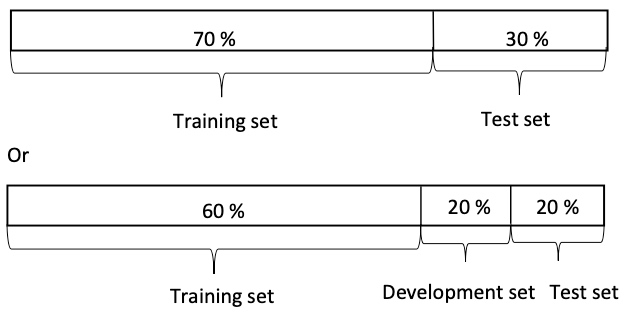
Modern era (Big data era)
Now, because a large amount of data is available, we don’t have to compromised as much and can use a greater portion to train the model.

Guidelines:
- Set up the size of the test set to give a high confidence in the overall performance of the system.
- Test set helps evaluate the performance of the final classifier which could be less 30% of the whole data set.
- The development set has to be big enough to evaluate different ideas.
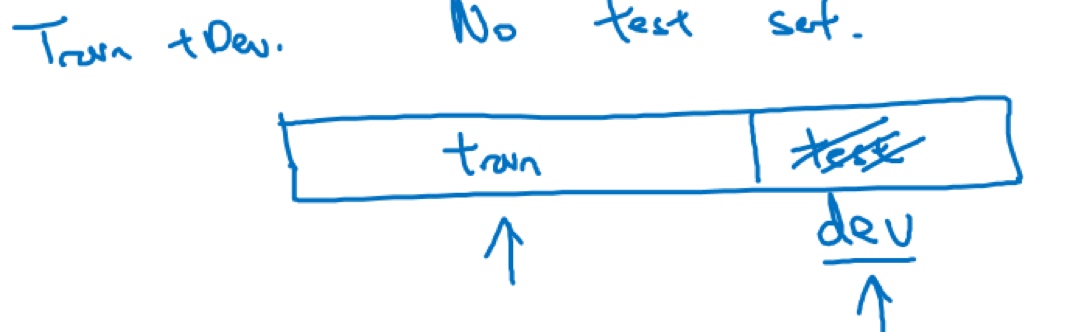
有时在实践中有些人会只分成训练集和测试集,他们实际上在测试集上迭代,所以这里没有测试集,他们有的是训练集和开发集,但没有测试集
什么时候该改变开发/测试集和指标?(When to change dev/test sets and metrics)
Example: Cat vs Non-cat
A cat classifier tries to find a great amount of cat images to show to cat loving users. The evaluation metric used is a classification error.
| Algorithm | Classification error [%] |
|---|---|
| A | 3% |
| B | 5% |
It seems that Algorithm A is better than Algorithm B since there is only a 3% error, however for some reason, Algorithm A is letting through a lot of the pornographic images.
Algorithm B has 5% error thus it classifies fewer images but it doesn’t have pornographic images. From a company’s point of view, as well as from a user acceptance point of view, Algorithm B is actually a better algorithm. The evaluation metric fails to correctly rank order preferences between algorithms. The evaluation metric or the development set or test set should be changed.
The misclassification error metric can be written as a function as follow:
$Error= \frac{1}{m_{dev}}\sum_{i=1}^{m_{dev}}L\{\tilde{y}^{(i)} \neq y^{(i)} \}$
This function counts up the number of misclassified examples.
The problem with this evaluation metric is that it treats pornographic vs non-pornographic images equally. On way to change this evaluation metric is to add the weight term 𝑤 (修改评估指标的方法):
$$
\begin{equation}
w^{(i)} =
\left\{
\begin{array}{lr}
1 & if\;x^{(i)}\;is\;non-pornograhic \\
10 & if\;x^{(i)}\;is\;pornograhic \\
\end{array}
\right.
\end{equation}
$$
这样赋予了色情图片更大的权重,让算法将色情图分类为猫图时,错误率这个项快速变大
如果希望得到归一化常数,在技术上,就是$w^{(i)}$对所有i求和,这样错误率仍然在0和1之间, The function becomes:
$Error= \frac{1}{\sum w^{(i)}}\sum_{i=1}^{m_{dev}} w^{(i)}L\{\tilde{y}^{(i)} \neq y^{(i)} \}$
实际上要使用这种加权,你必须自己过一遍开发集和测试集,在开发集和测试集里,自己把色情图片标记出来,这样你才能使用这个加权函数
Guideline:
- Define correctly an evaluation metric that helps better rank order classifiers
- Optimize the evaluation metric
为什么是人的表现?(Why human-level performance?)
Today, machine learning algorithms can compete with human-level performance since they are more productive and more feasible in a lot of application. Also, the workflow of designing and building a machine learning system, is much more efficient than before.
Moreover, some of the tasks that humans do are close to “perfection”, which is why machine learning tries to mimic human-level performance.
The graph below shows the performance of humans and machine learning over time.
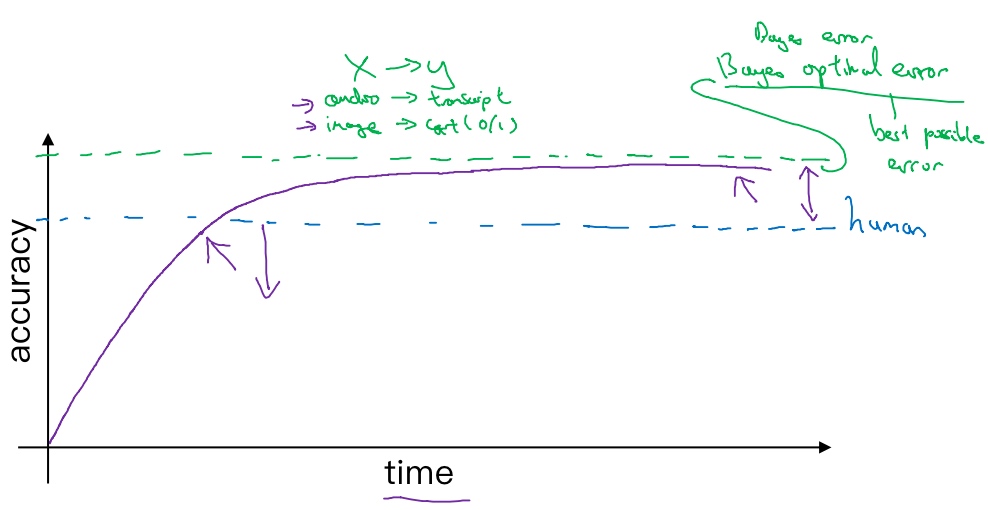
The Machine learning progresses slowly when it surpasses human-level performance. One of the reason is that human-level performance can be close to Bayes optimal error(贝叶斯最优错误率), especially for natural perception problem.
Bayes optimal error is defined as the best possible error. In other words, it means that any functions mapping from x to y can’t surpass a certain level of accuracy. (没有任何办法设计出一个x到y的函数,让它能够超过一定的准确度)
当模型超越人类的表现时,有时进展会变慢, 有两个原因:
- 人类水平在很多任务中离贝叶斯最优错误率已经不远了,E.g.人们非常擅长看图像
- 只要模型的表现比人类的表现更差,那么实际上可以使用某些工具来提高性能。一旦你超越了人类的表现,这些工具就没那么好用了
Also, when the performance of machine learning is worse than the performance of humans, you can improve it with different tools. They are harder to use once its surpasses human-level performance.
These tools are:
- Get labeled data from humans (让人帮你标记数据, 这样就有更多的数据可以喂给学习算法)
- Gain insight from manual error analysis: Why did a person get this right? (人工错误率分析)
- Better analysis of bias/variance.
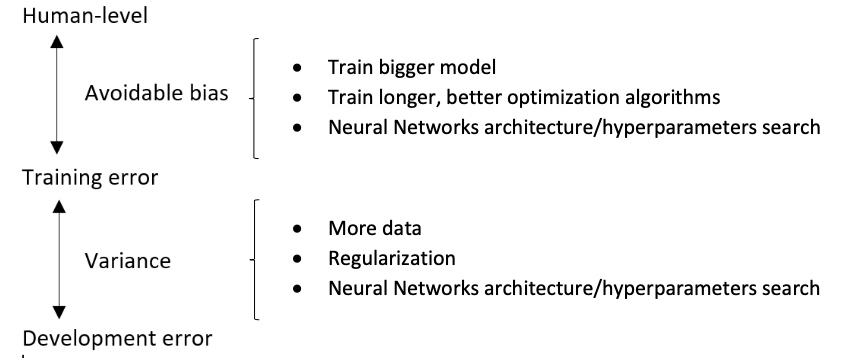
可避免偏差(Avoidable bias)
By knowing what the human-level performance is, it is possible to tell when a training set is performing well or not.
Example: Cat vs Non-Cat
Classification error (%)
| Scenario A | Scenario B | |
|---|---|---|
| Humans | 1% | 7.5% |
| Training error | 8% | 8% |
| Dev error | 10% | 10% |
In this case, the human level error as a proxy for Bayes error since humans are good to identify images. If you want to improve the performance of the training set but you can’t do better than the Bayes error otherwise the training set is overfitting. By knowing the Bayes error, it is easier to focus on whether bias or variance avoidance tactics will improve the performance of the model.
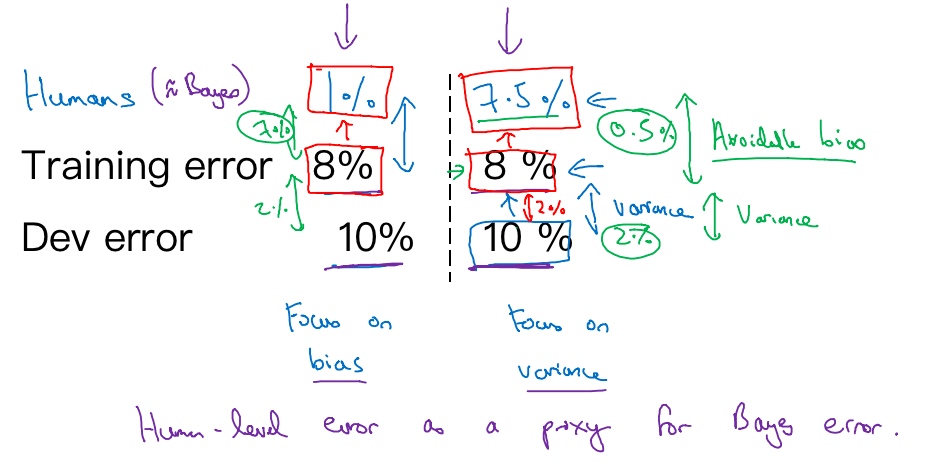
Scenario A
There is a 7% gap between the performance of the training set and the human level error. It means that the algorithm isn’t fitting well with the training set since the target is around 1%. To resolve the issue, we use bias reduction technique such as training a bigger neural network or running the training set longer.
Scenario B
The training set is doing good since there is only a 0.5% difference with the human level error. The difference between the training set and the human level error is called avoidable bias. The focus here is to reduce the variance since the difference between the training error and the development error is 2%. To resolve the issue, we use variance reduction technique such as regularization or have a bigger training set.
理解人的表现(Understanding human-level performance)
Human-level error gives an estimate of Bayes error.

Example 1: Medical image classification
This is an example of a medical image classification in which the input is a radiology image and the output is a diagnosis classification decision.
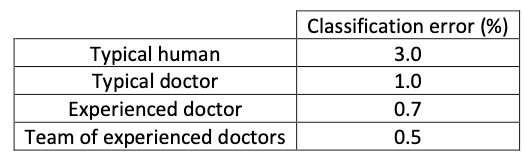
The definition of human-level error depends on the purpose of the analysis, in this case, by definition the Bayes error is lower or equal to 0.5%.
Example 2: Error analysis
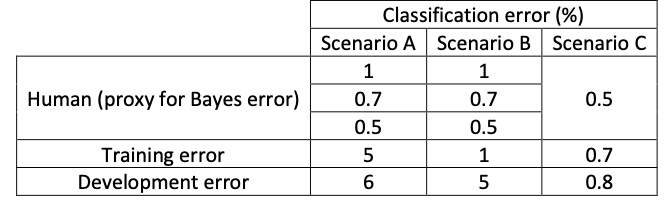
Scenario A
In this case, the choice of human-level performance doesn’t have an impact. The avoidable bias is between 4%-4.5% and the variance is 1%. Therefore, the focus should be on bias reduction technique.
Scenario B
In this case, the choice of human-level performance doesn’t have an impact. The avoidable bias is between 0%-0.5% and the variance is 4%. Therefore, the focus should be on variance reduction technique.
Scenario C
In this case, the estimate for Bayes error has to be 0.5% since you can’t go lower than the human-level performance otherwise the training set is overfitting. Also, the avoidable bias is 0.2% and the variance is 0.1%. Therefore, the focus should be on bias reduction technique.
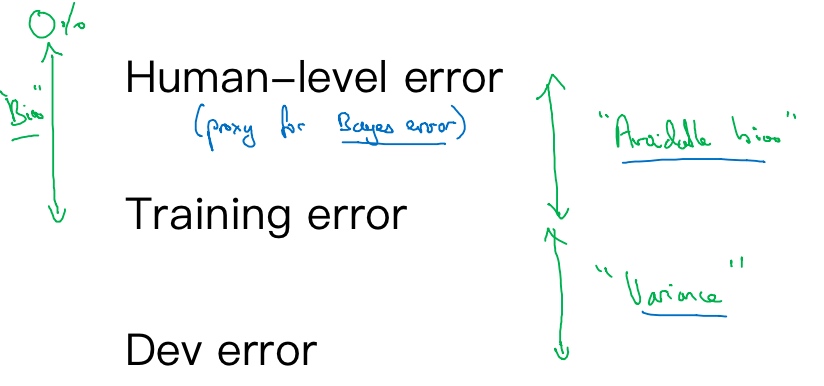
Summary of bias/variance with human-level performance
- Human - level error – proxy for Bayes error
- If the difference between human-level error and the training error is bigger than the difference between the training error and the development error. The focus should be on bias reduction technique
- If the difference between training error and the development error is bigger than the difference between the human-level error and the training error. The focus should be on variance reduction technique
超过人的表现(Surpassing human- level performance)
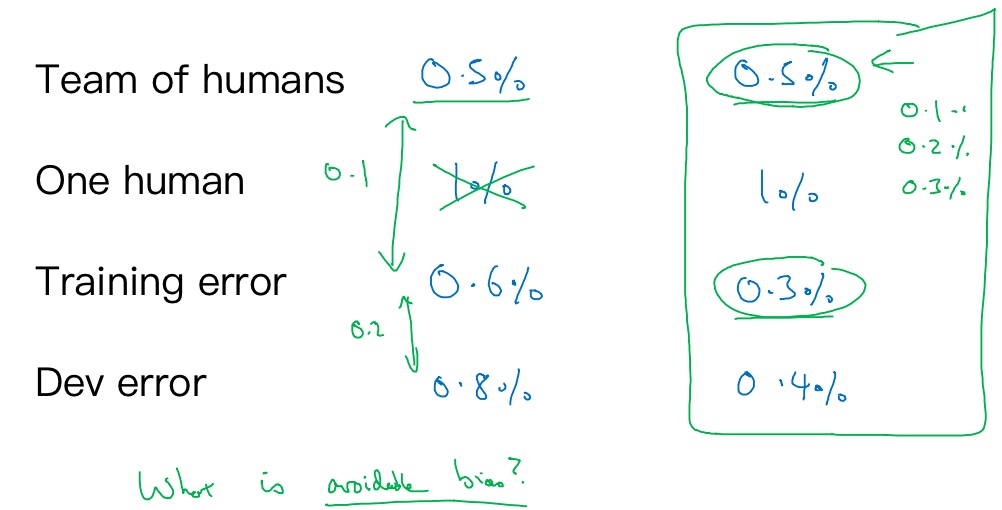
Example1: Classification task
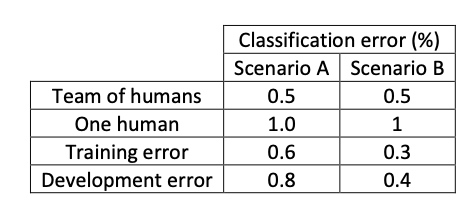
Scenario A
In this case, the Bayes error is 0.5%, therefore the available bias is 0.1% et the variance is 0.2%.
Scenario B
In this case, there is not enough information to know if bias reduction or variance reduction has to be done on the algorithm. It doesn’t mean that the model cannot be improve, it means that the conventional ways to know if bias reduction or variance reduction are not working in this case.
There are many problems where machine learning significantly surpasses human-level performance, especially with structured data:
- Online advertising
- Product recommendations
- Logistics (predicting transit time)
- Loan approvals
- …
BUT not natural perception aspect:
- Speech recognition
- Image recognition
- …
改善你的模型的表现(Improving your model performance)
The two fundamental assumptions of supervised learning
There are 2 fundamental assumptions of supervised learning. The first one is to have a low avoidable bias which means that the training set fits well. The second one is to have a low or acceptable variance which means that the training set performance generalizes well to the development set and test set.
If the difference between human-level error and the training error is bigger than the difference between the training error and the development error, the focus should be on bias reduction technique which are training a bigger model, training longer or change the neural networks architecture or try various hyperparameters search. If the difference between training error and the development error is bigger than the difference between the human-level error and the training error, the focus should be on variance reduction technique which are bigger data set, regularization or change the neural networks architecture or try various hyperparameters search.
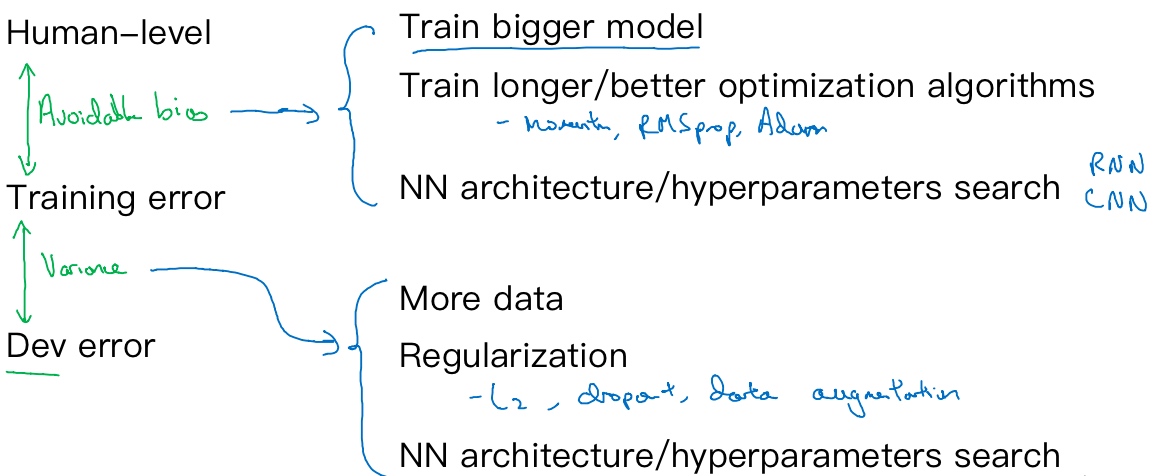
Summary